![]()
Get NCP-MCI-6.5 Braindumps & NCP-MCI-6.5 Real Exam Questions
Nutanix NCP-MCI-6.5 Actual Questions and Braindumps
NEW QUESTION # 79
After deploying a cluster, time is not synchronizing properly.
What task needs to be performed?
- A. SMTP configuration
- B. HA configuration
- C. DNS configuration
- D. NTP configuration
Answer: D
Explanation:
The task that needs to be performed when time is not synchronizing properly after deploying a cluster is NTP configuration. In the Nutanix Multicloud Infrastructure (NCP-MCI) 6.5, Network Time Protocol (NTP) is used to synchronize the system time across all the nodes in a cluster. If the time is not synchronizing properly, it indicates that there might be an issue with the NTP configuration. Therefore, checking and correcting the NTP configuration would be the appropriate action to resolve this issue. The other options like DNS configuration, HA configuration, and SMTP configuration are not directly related to time synchronization in a cluster.
NEW QUESTION # 80
Which component ensures uniform distribution of data throughout the cluster to eliminate hot spots and speed up rebuilds?
- A. Cassandra
- B. High Availability
- C. Distributed Storage Fabric
- D. Acropolis App Mobility Fabric
Answer: C
Explanation:
According to the web search results, Distributed Storage Fabric (DSF) is the scale-out storage technology that makes HCI and cloud possible45. DSF pools the storage devices that are directly attached to a cluster of servers and presents them to applications across a variety of storage protocols4. DSF also manages and protects data by a fine-grained, distributed metadata system that ensures uniform distribution of data throughout the cluster to eliminate hot spots and speed up rebuilds
NEW QUESTION # 81
The administrator recently had a node fail in an AHV Nutanix cluster. All of the VMs restarted on other nodes in the cluster, but they discovered that the VMs that make up a SQL cluster were running on the failed host.
The administrator has been asked to take measures to prevent a SQL outage in the future.
What affinity option will prevent the SQL VMs from running on the same hos?
- A. VM-Most Affinity policy
- B. VM-VM anti-Affinity policy
- C. Create Affinity Project
- D. Create Affinity Category
Answer: B
NEW QUESTION # 82
Refer to the exhibit.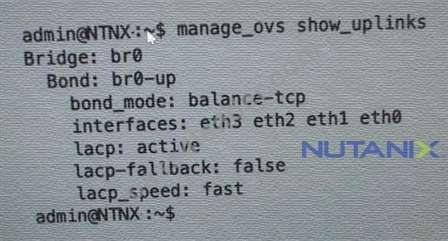
An administrator is adding a new node to a cluster. The node has been imaged to the same versions of AHV and AOS that the cluster running, configured with appropriate IP addresses, and br0-up has been configured the same the existing uplink bonds When attempting to add the node to the cluster with the Expand Cluster function in Prism , the cluster is unable to find the new node.
Based on the above output from the new node, what is most likely the cause of this issue?
- A. The existing and the expansion node are on different VLANs.
- B. LACP configuration must be completed after cluster expansion
- C. There is a firewall blocking the discovery traffic from the tlu
- D. The ports on the upstream switch are not configured for LACP.
Answer: A
Explanation:
The correct answer is B. The existing and the expansion node are on different VLANs.
The output shows that the new node has a br0-up bond with four interfaces: eth0, eth1, eth2, and eth3. The bond is configured with LACP active and LACP fallback set to false. This means that the bond will only work if the upstream switch supports LACP and is configured to form an LACP group with the four interfaces.
However, the output also shows that the bond has no IP address assigned to it, which indicates that the bond is not operational. One possible reason for this is that the existing and the expansion node are on different VLANs, and the upstream switch is not configured to allow the VLAN traffic on the LACP group. This would prevent the new node from communicating with the cluster and being discovered by the Expand Cluster function in Prism.
To verify this, the administrator can check the VLAN configuration on the upstream switch and compare it with the existing nodes. Alternatively, the administrator can use the "manage_ovs show_uplinks" command on an existing node and compare the output with the new node. If there is a VLANmismatch, the administrator can either change the VLAN configuration on the switch or on the new node to match the existing nodes.
NEW QUESTION # 83
Refer to the exhibit.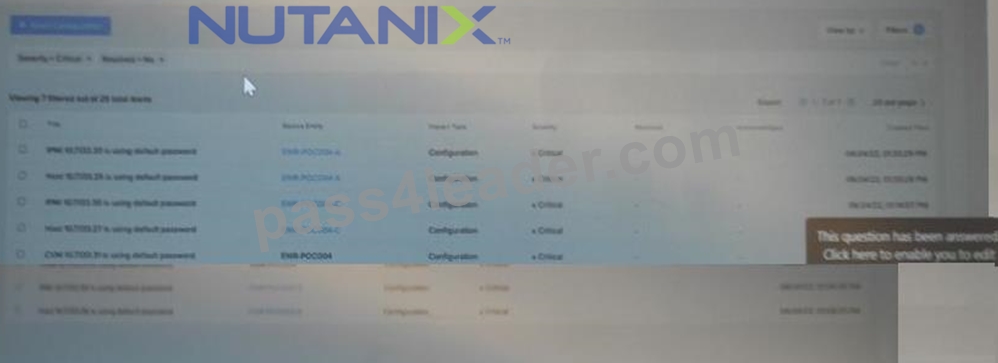
Which two initial cluster configuration tasks were missed during the deployment process? (Choose two.)
- A. BIOS password changes
- B. CVM password changes
- C. Host password changes
- D. Password policy changes
Answer: B,C
NEW QUESTION # 84
Refer to the exhibit.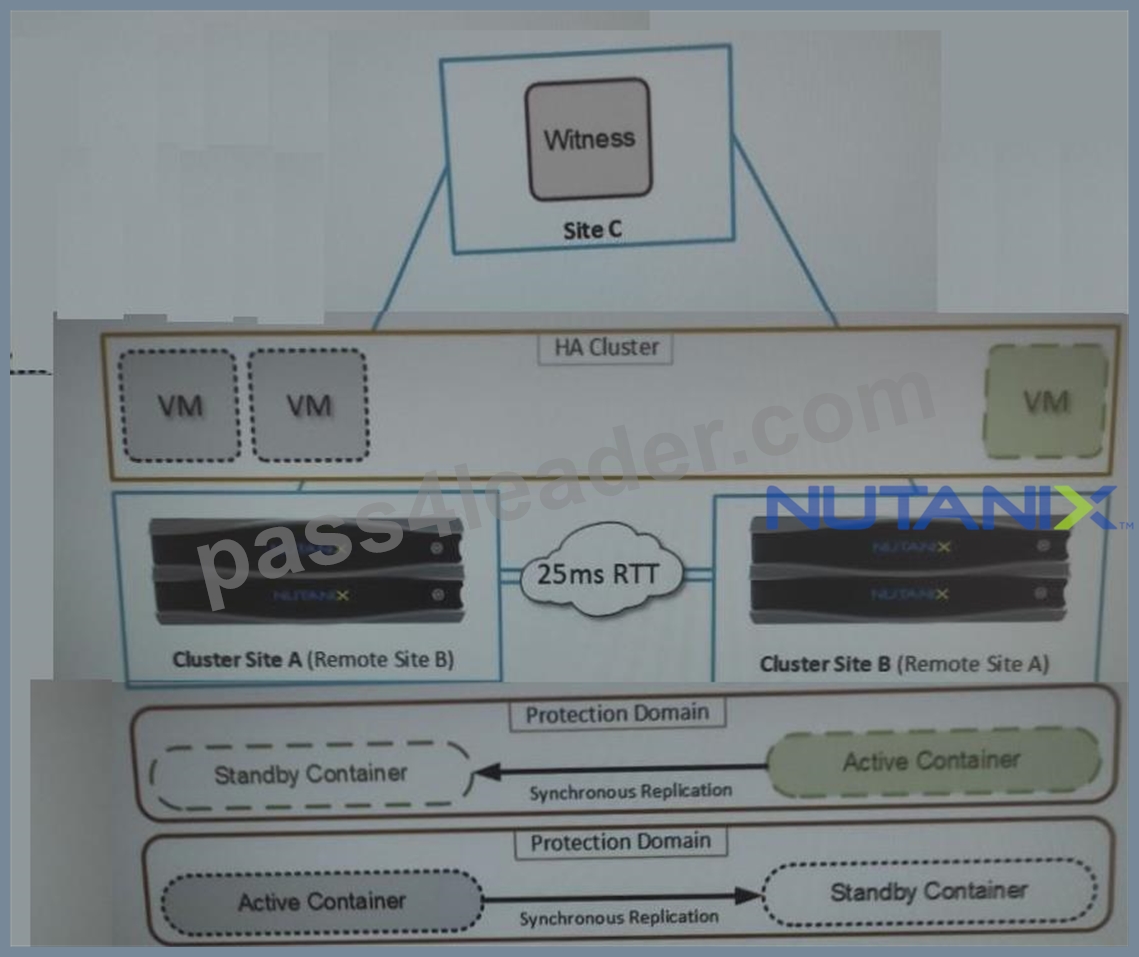
An administrator is trying to implement the solution that is shown in the exhibit, but has been unsuccessful.
Based on the diagram, what is causing the issue?
- A. Network latency
- B. Active containers in both sites
- C. Unsupported hypervisor
- D. A remote Witness VM
Answer: A
NEW QUESTION # 85
An administrator needs to limit the amount of storage space that data stored in single container can consume.
Which action should the administrator take?
- A. Enable reservation for rebuild capacity
- B. Set an advertised capacity for the container
- C. Thick prevision the container
- D. Store VM snapshots in a different container
Answer: B
Explanation:
Explanation
The best way for the administrator to limit the amount of storage space that data stored in a single container can consume is to set an advertised capacity for the container. This will ensure that the data stored in the container doesn't exceed the set limit, and it will also help prevent any potential performance issues due to resource contention. Additionally, the administrator should consider thick provisioning the container, which will pre-allocate the amount of storage space that can be used by the container. This will help ensure that the data stored in the container doesn't exceed the advertised capacity.
NEW QUESTION # 86
An administrator initially performed a cluster Foundation using a flat switch without any VLAN configuration.
After the Foundation, the administrator moved the dual 25Gb data ports and single 1Gb IPMI port to the actual switches with the below network configurations:
. All VLANs are tagged
. VLAN 1000 for CVM\Hypervisor traffic
VLAN 1001 for User VM traffic
. VLAN 100 for IPMI traffic
After moving the IPMI network links, the administrator can no longer ping the IPMI IPs.
Which two changes does the administrator need to make? (Choose two.)
- A. SSH to AHV and set the VLAN ID using IPMI Tool.
- B. SSH to AHV and change the IP address using IPMI tool.
- C. SSH to CVM and restart Genesis on all CVMs.
- D. SSH to CVM and restart network services on all host.
Answer: A,B
Explanation:
The issue described pertains to the inability to ping the IPMI IPs after moving the IPMI network links to the actual switches with specific VLAN configurations. The two changes that the administrator needs to make are:
A: SSH to AHV and set the VLAN ID using IPMI Tool: Since all VLANs are tagged in the new network configuration, the IPMI network interface needs to be aware of the VLAN it's supposed to communicate on.
This can be achieved by setting the VLAN ID using the IPMI Tool on the AHV.
C: SSH to AHV and change the IP address using IPMI tool: If the IPMI IP addresses were initially set in a different subnet that is not routable in the new network configuration, the administrator would need to change the IPMI IP addresses to match the new network configuration. This can be done by SSHing to the AHV and using the IPMI Tool to change the IP address.
NEW QUESTION # 87
An administrator has created a Nutanix managed it a VLAN ID of 512.
Several VMs have been created, and the administrator notices that the can successfully communicate with other VMs on that VLAN.
Provided they are on the host, but cannot communicate with VMs that reside on different hosts in the cluster.
What is most likely thee cause of this issue?
- A. There is a firewall rule blockingVLAN512 traffic.
- B. The administrator did not create the VLAN on all hosts
- C. VLANS12 is a reserved VLAN ID, and not usable for guest VMs.
- D. The VLAN was not created on the upstream switches.
Answer: D
NEW QUESTION # 88
On a Nutanix cluster, what does Network Segmentation refer to?
- A. Isolating management traffic from storage replication traffic.
- B. Isolating intra-cluster traffic from guest VM traffic.
- C. Physically separating management traffic from guest VM traffic.
- D. A distributed firewall for security VM to VM traffic.
Answer: B
Explanation:
network segmentation on Nutanix clusters refers to creating a separate network for service-specific communication and isolating different types of traffic over selected VLANs or physical interfaces.
https://next.nutanix.com/ncm-intelligent-operations-formerly-prism-pro-ultimate-26/network-segmentation-isolating-service-specific-traffic-39463
https://next.nutanix.com/how-it-works-22/network-segmentation-basics-38414
NEW QUESTION # 89
Which two capabilities does IPAM provide in a Nutanix networking configuration? (Choose two.)
- A. Allows proxy server settings to be set up for a defined network
- B. Configures a VLAN with an IP subnet and assigns a group of IP addresses
- C. Configures firewall rules to prevent or allow certain TCP/IP traffic
- D. Allows AHV to assign IP addresses automatically to VMs using DHCP
Answer: B,D
Explanation:
According to the Nutanix Support & Insights, IPAM enables AHV to assign IP addresses automatically to VMs using DHCP. You can configure each virtual network and associated VLAN with a specific IP subnet, associated domain settings, and group of IP address pools available for assignment.
NEW QUESTION # 90
Refer to Exhibit: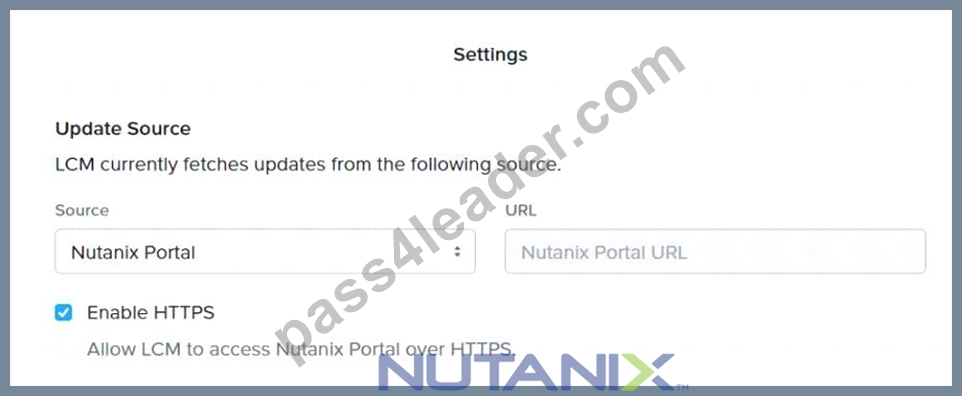
The Update Source for LCM has been configured as shown in the exhibit. Inventory is failing consistently.
What is the likely cause of this issue?
- A. The license assigned to the cluster has expired.
- B. Port 433 Is blocked by a firewall.
- C. The administrator does not have a valid portal account.
- D. Port 80 is blocked by a firewall.
Answer: B
Explanation:
https://hyperhci.com/2019/07/22/nutanix-lcm-upgrade-process-failed-trouble-shooting/
NEW QUESTION # 91
What requires iSCSI initiator configuration in the guest OS to use Volumes?
- A. Exchange DAG
- B. Oracle RAC
- C. Microsoft Windows Failover Cluster
- D. SQL Server Always On Availability Group
Answer: C
Explanation:
The only option that requires iSCSI initiator configuration in the guest OS to use Volumes is Microsoft Windows Failover Cluster. Volumes is an enterprise-class, software-defined block storage solution that exposesstorage resources directly to virtualized guest operating systems or physical hosts using the iSCSI protocol7. To use Volumes, customers need toconfigure iSCSI initiators on their hosts or guest OSes.
However, some applications or services can use native storage adapters instead of iSCSI initiators when running on AHV VMs. These include:
* SQL Server Always On Availability Group: This is a high availability and disaster recovery solution for SQL Server databases that uses Windows Server Failover Clustering (WSFC) and Availability Groups (AGs) as its core components. When running on AHV VMs, SQL Server Always On Availability Group can use native storage adapters instead of iSCSI initiators.
* Oracle RAC: This is a clustered database system that provides high availability and scalability for Oracle databases. When running on AHV VMs, Oracle RAC can use native storage adapters instead of iSCSI initiators.
* Exchange DAG: This is a group of up to 16 mailbox servers that hosts a set of databases and provides automatic database-level recovery from failures that affect individual servers or databases. When running on AHV VMs, Exchange DAG can use native storage adapters instead of iSCSI initiators.
NEW QUESTION # 92
An administrator manages an AHV cluster that is dedicated to a dev/test environment. The administrator receiving complaints from users that they are unable to create new VMs on the cluster.
After the reviewing the cluster, the administrator finds that the memory resources are almost fully utilized, with many VMs over-provisioned on memory.
What option is the most efficient resolution to enable additional VMs to be created?
- A. Upgrade the nodes with additional memory DlMMs.
- B. Enable Memory Overcommit on the over-provisioned VMs.
- C. Enable Memory HA on the over-provisioned VMs.
- D. Disable HA Reservation on the cluster.
Answer: B
Explanation:
Enable Memory Overcommit on the over-provisioned VMs is the most efficient resolution to enable additional VMs to be created. Memory overcommit allows VMs to use more memory than physically available on a host by compressing and swapping memory pages to storage1. This can improve memory utilization and increase VM density on a cluster1. However, memory overcommit is not supported when HA is configured to use reserved hosts, so you may need to disable HA reservation on the cluster before enabling memory overcommit1.
NEW QUESTION # 93
Refer to the exhibit.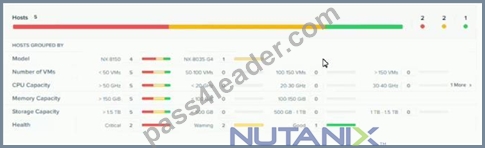
System Non-Root Partition Usage shows a warning or critical alert The administrator needs to change the frequency of checks and alerts to respond more quickly.
Where in Prism Element should the administrator change the frequency of checks and alerts?
- A. Health Dashboard > Manage Crocks > Frequency
- B. Alerts Dashboard > Manage Checks > Schedule
- C. Alerts Dashboard > Manage Checks > Frequency
- D. Health Dashboard > Manage Checks > Schedule
Answer: D
Explanation:
According to the Nutanix Support & Insights web search result1, the administrator can change the frequency of checks and alerts for the System Non-Root Partition Usage in Prism Element by going to the Health Dashboard > Manage Checks > Schedule. The administrator can select the check name, such as disk_usage_check, and click on Edit Schedule. The administrator can then choose the desired frequency, such as every 15 minutes, every hour, or every day, and click on Save. This will change how often the check runs and alerts are generated.
NEW QUESTION # 94
Which capability refers to the storage of VM data on the node where the VM is running and ensure that the read I/O does not have to traverse the network?
- A. Intelligent Locally
- B. Intelligent Tiering
- C. Data Locality
- D. Data Tiering
Answer: C
Explanation:
Data locality is the capability of storing VM data on the node where the VM is running and ensuring that the read I/O does not have to traverse the network. Data locality is a unique feature of Nutanix that provides high performance and low latency for VMs by minimizing network traffic and crosstalk. Data locality works by writing one copy of the data local to the VM and the other copy (or copies) on other nodes. When a VM migrates to another node, Nutanix also moves its data to the new node and serves all I/O requests locally. Data locality also adapts to changing workloads and access patterns by dynamically moving data to where it is needed most1.
NEW QUESTION # 95
Refer to Exhibit: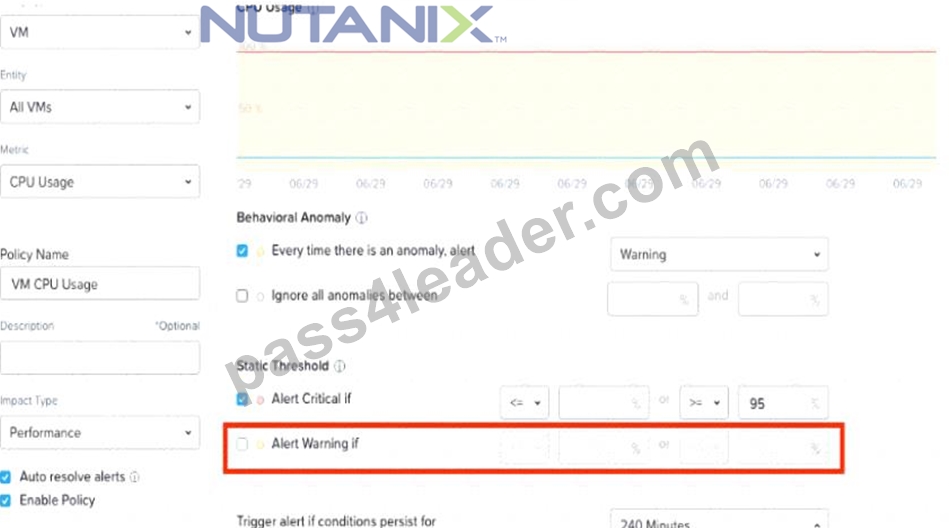
An administrator is trying to create a custom alert policy for all VMs.
Why is the Alert warning if field greyed cut?
- A. The Behavioral Anomaly threshold is set.
- B. The Alert critical if threshold is set.
- C. The Enable Policy option checked.
- D. The Auto resolve alerts option is checked.
Answer: A
Explanation:
when you create a custom alert policy, you can choose between two types of thresholds: Static Threshold and Behavioral Anomaly. Static Threshold allows you to set a fixed value for the metric that triggers the alert.
Behavioral Anomaly allows you to use machine learning to detect abnormal behavior based on historical data.
If you select Behavioral Anomaly as the threshold type, you cannot set a warning level for the alert. You can only set a critical level that indicates how much deviation from normal behavior is considered an anomaly3.
Therefore, the Alert warning if field is greyed out when you select Behavioral Anomaly.
NEW QUESTION # 96
An administrator needs to shut down an AHV cluster to relocate hardware. The administrator upgrades NCC and runs health checks.
Which steps should the administrator perform next?
Item instructions: For each procedure, indicate the order in which that procedure must take place to meet the item requirements.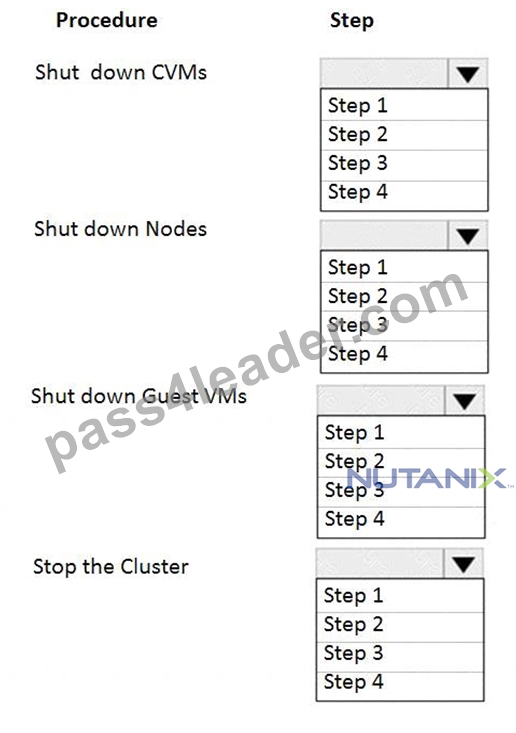
Answer:
Explanation: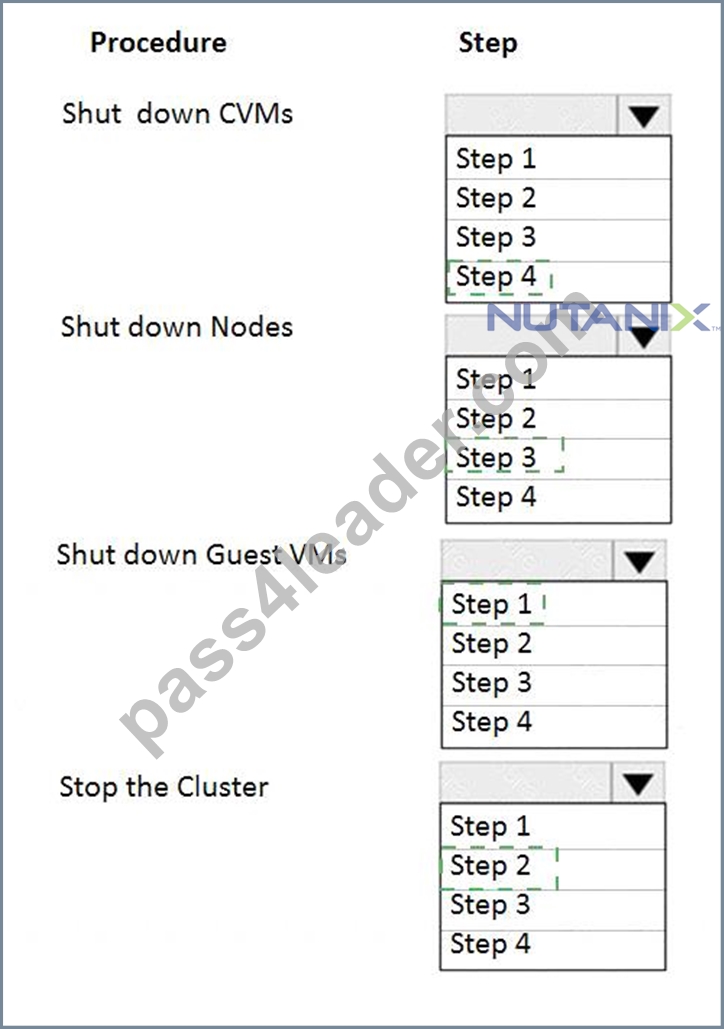
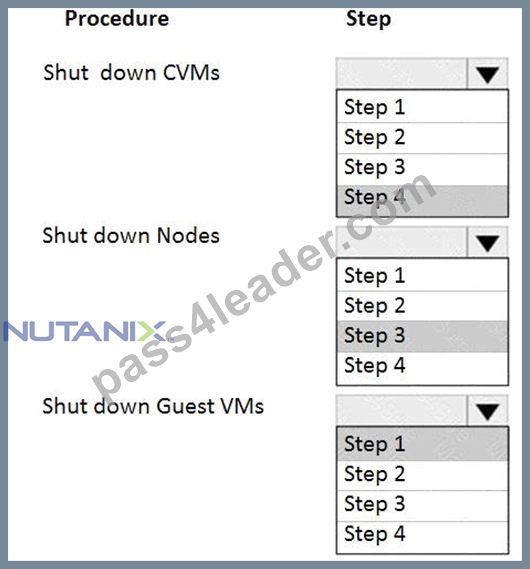
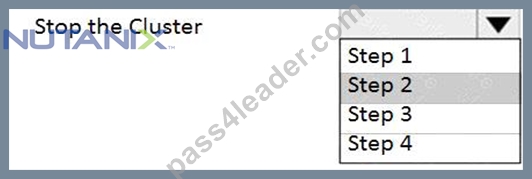
NEW QUESTION # 97
......
NCP-MCI-6.5 Dumps To Pass Nutanix Exam in 24 Hours - Pass4Leader: https://www.pass4leader.com/Nutanix/NCP-MCI-6.5-exam.html
Buy Latest NCP-MCI-6.5 Exam Q&A PDF - One Year Free Update: https://drive.google.com/open?id=1pI0oLz-VxINADblp5uYfAA0V3RY_gUtA