![]()
Get Latest [Sep-2021] Conduct effective penetration tests using Pass4Leader DP-200
Penetration testers simulate DP-200 exam PDF
NEW QUESTION 78
You need to provision the polling data storage account.
How should you configure the storage account? To answer, drag the appropriate Configuration Value to the correct Setting. Each Configuration Value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation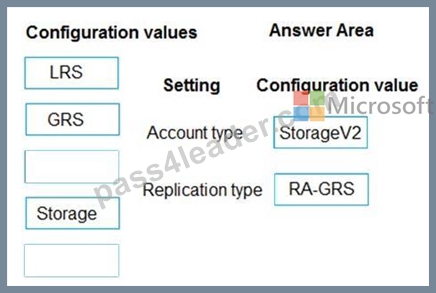
Account type: StorageV2
You must create new storage accounts as type StorageV2 (general-purpose V2) to take advantage of Data Lake Storage Gen2 features.
Scenario: Polling data is stored in one of the two locations:
* An on-premises Microsoft SQL Server 2019 database named PollingData
* Azure Data Lake Gen 2
Data in Data Lake is queried by using PolyBase
Replication type: RA-GRS
Scenario: All services and processes must be resilient to a regional Azure outage.
Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9's) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn't recoverable.
If you opt for GRS, you have two related options to choose from:
* GRS replicates your data to another data center in a secondary region, but that data is available to be read only if Microsoft initiates a failover from the primary to secondary region.
* Read-access geo-redundant storage (RA-GRS) is based on GRS. RA-GRS replicates your data to another data center in a secondary region, and also provides you with the option to read from the secondary region. With RA-GRS, you can read from the secondary region regardless of whether Microsoft initiates a failover from the primary to secondary region.
References:
https://docs.microsoft.com/bs-cyrl-ba/azure/storage/blobs/data-lake-storage-quickstart-create-account
https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
NEW QUESTION 79
You have data stored in thousands of CSV files in Azure Data Lake Storage Gen2. Each file has a header row followed by a property formatted carriage return (/r) and line feed (/n).
You are implementing a pattern that batch loads the files daily into an Azure SQL data warehouse by using PolyBase.
You need to skip the header row when you import the files into the data warehouse.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Which three actions you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Explanation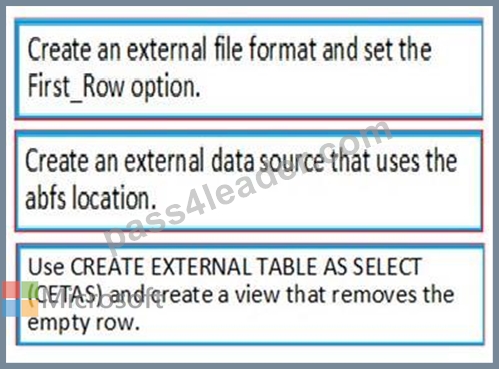
Step 1: Create an external data source and set the First_Row option.
Creates an External File Format object defining external data stored in Hadoop, Azure Blob Storage, or Azure Data Lake Store. Creating an external file format is a prerequisite for creating an External Table.
FIRST_ROW = First_row_int
Specifies the row number that is read first in all files during a PolyBase load. This parameter can take values
1-15. If the value is set to two, the first row in every file (header row) is skipped when the data is loaded.
Rows are skipped based on the existence of row terminators (/r/n, /r, /n).
Step 2: Create an external data source that uses the abfs location
The hadoop-azure module provides support for the Azure Data Lake Storage Gen2 storage layer through the
"abfs" connector
Step 3: Use CREATE EXTERNAL TABLE AS SELECT (CETAS) and create a view that removes the empty row.
References:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-file-format-transact-sql
https://hadoop.apache.org/docs/r3.2.0/hadoop-azure/abfs.html
NEW QUESTION 80
Use the following login credentials as needed:
Azure Username: xxxxx
Azure Password: xxxxx
The following information is for technical support purposes only:
Lab Instance: 10543936
You need to double the available processing resources available to an Azure SQL data warehouse named datawarehouse.
To complete this task, sign in to the Azure portal.
NOTE: This task might take several minutes to complete.
You can perform other tasks while the task completes or end this section of the exam.
Answer:
Explanation:
See the explanation below.
Explanation
SQL Data Warehouse compute resources can be scaled by increasing or decreasing data warehouse units.
1. Click SQL data warehouses in the left page of the Azure portal.
2. Select datawarehouse from the SQL data warehouses page. The data warehouse opens.
3. Click Scale.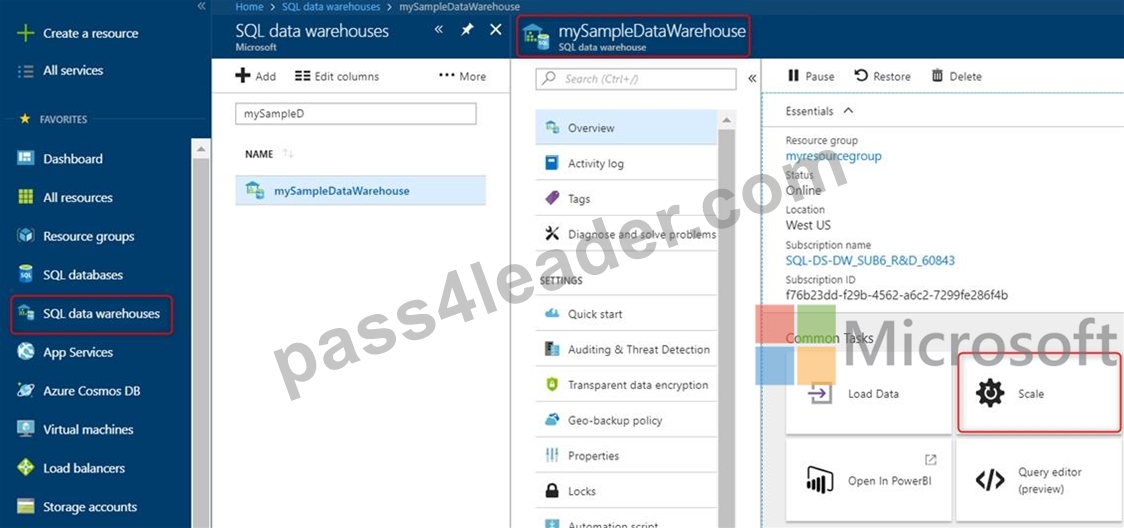
4. In the Scale panel, move the slider left or right to change the DWU setting. Double the DWU setting.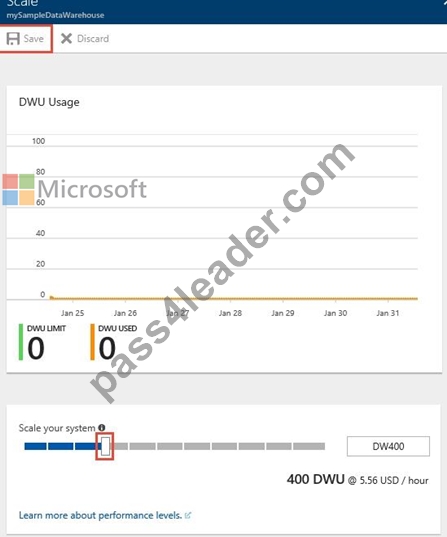
6. Click Save. A confirmation message appears. Click yes to confirm or no to cancel.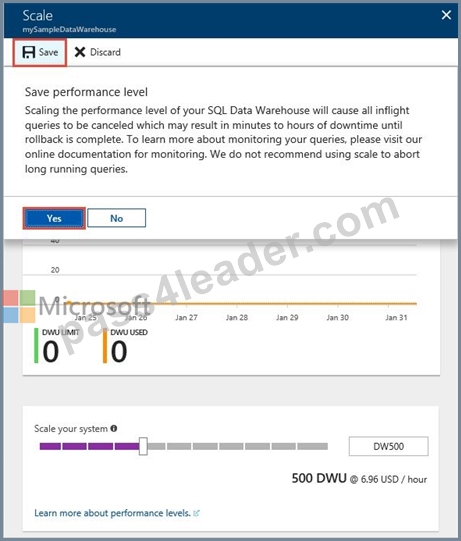
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/quickstart-scale-compute-portal
NEW QUESTION 81
You have a SQL pool in Azure Synapse that contains a table named dbo.Customers. The table contains a column name Email.
You need to prevent nonadministrative users from seeing the full email addresses in the Email column. The users must see values in a format of [email protected] instead.
What should you do?
- A. From Microsoft SQL Server Management Studio, set an email mask on the Email column.
- B. From Microsoft SQL Server Management studio, grant the SELECT permission to the users for all the columns in the dbo.Customers table except Email.
- C. From the Azure portal, set a mask on the Email column.
- D. From the Azure portal, set a sensitivity classification of Confidential for the Email column.
Answer: C
Explanation:
Explanation/Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/dynamic-data-masking-overview
NEW QUESTION 82
You need to receive an alert when Azure SQL Data Warehouse consumes the maximum allotted resources.
Which resource type and signal should you use to create the alert in Azure Monitor? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.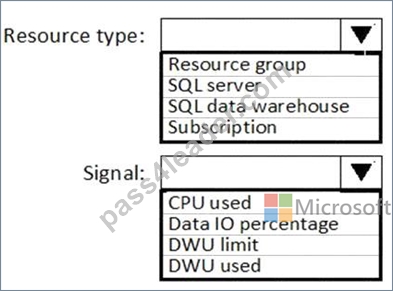
Answer:
Explanation: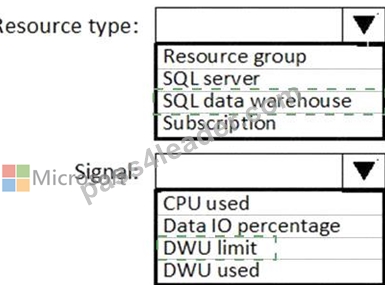
Explanation
Resource type: SQL data warehouse
DWU limit belongs to the SQL data warehouse resource type.
Signal: DWU limit
SQL Data Warehouse capacity limits are maximum values allowed for various components of Azure SQL Data Warehouse.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-insights-alerts-portal
NEW QUESTION 83
Use the following login credentials as needed:
Azure Username: xxxxx
Azure Password: xxxxx
The following information is for technical support purposes only:
Lab Instance: 10543936
You need to ensure that you can recover any blob data from an Azure Storage account named storage10543936 up to 10 days after the data is deleted.
To complete this task, sign in to the Azure portal.
Answer:
Explanation:
See the explanation below.
Explanation
Enable soft delete for blobs on your storage account by using Azure portal:
1. In the Azure portal, select your storage account.
2. Navigate to the Data Protection option under Blob Service.
3. Click Enabled under Blob soft delete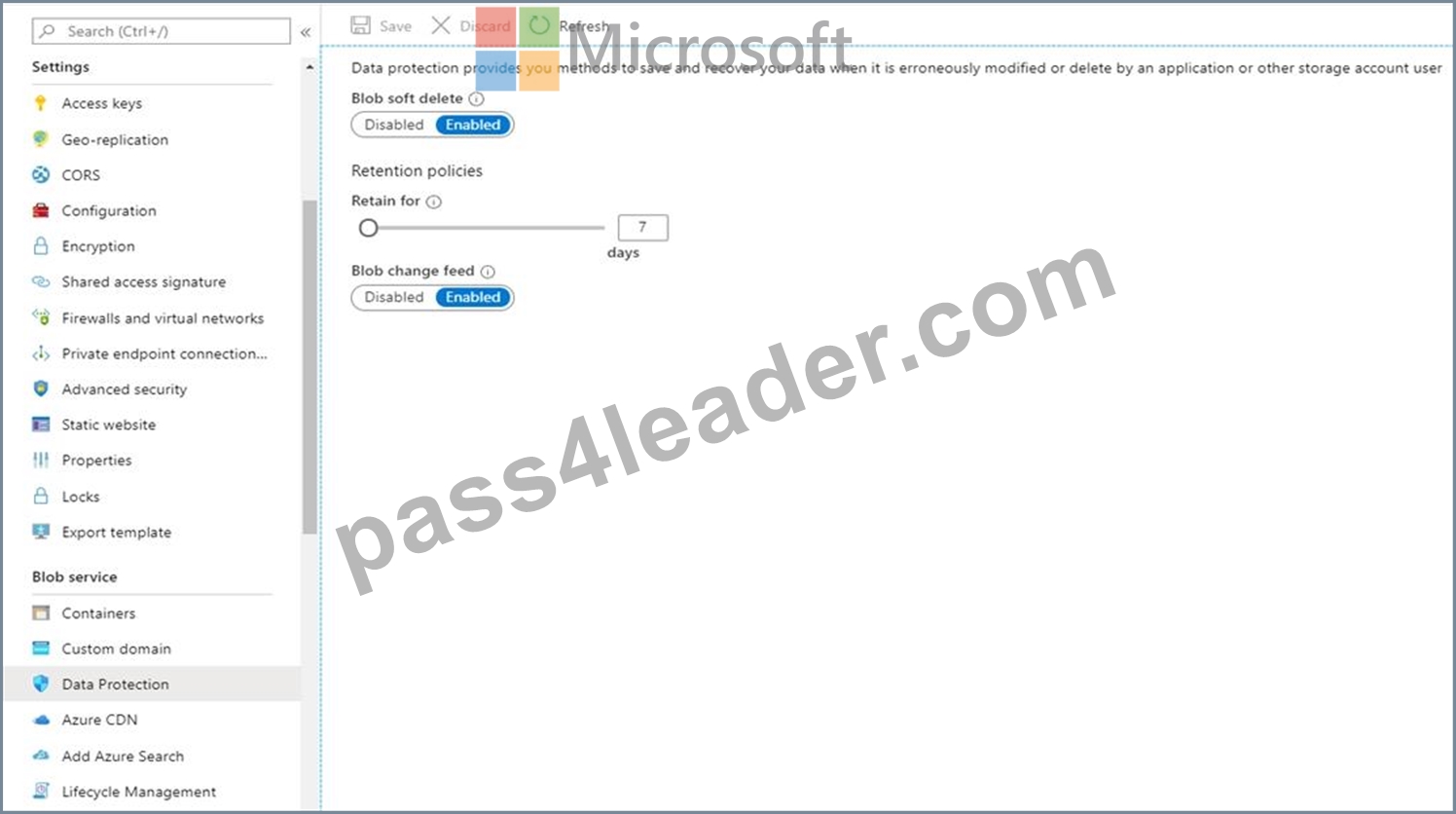
4. Enter the number of days you want to retain for under Retention policies. Here enter 10.
5. Choose the Save button to confirm your Data Protection settings
Note: Azure Storage now offers soft delete for blob objects so that you can more easily recover your data when it is erroneously modified or deleted by an application or other storage account user. Currently you can retain soft deleted data for between 1 and 365 days.
Reference:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blob-soft-delete
NEW QUESTION 84
A company plans to analyze a continuous flow of data from a social media platform by using Microsoft Azure Stream Analytics. The incoming data is formatted as one record per row.
You need to create the input stream.
How should you complete the REST API segment? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: CSV
A comma-separated values (CSV) file is a delimited text file that uses a comma to separate values. A CSV file stores tabular data (numbers and text) in plain text. Each line of the file is a data record.
JSON and AVRO are not formatted as one record per row.
Box 2: "type":"Microsoft.ServiceBus/EventHub",
Properties include "EventHubName"
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-define-inputs
https://en.wikipedia.org/wiki/Comma-separated_values
NEW QUESTION 85
You have a self-hosted integration runtime in Azure Data Factory.
The current status of the integration runtime has the following configurations:
Status: Running
Type: Self-Hosted
Running / Registered Node(s): 1/1
High Availability Enabled: False
Linked Count: 0
Queue Length: 0
Average Queue Duration: 0.00s
The integration runtime has the following node details:
Name: X-M
Status: Running
Available Memory: 7697MB
CPU Utilization: 6%
Network (In/Out): 1.21KBps/0.83KBps
Concurrent Jobs (Running/Limit): 2/14
Role: Dispatcher/Worker
Credential Status: In Sync
Use the drop-down menus to select the answer choice that completes each statement based on the information presented.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime
NEW QUESTION 86
You develop data engineering solutions for a company.
A project requires the deployment of data to Azure Data Lake Storage.
You need to implement role-based access control (RBAC) so that project members can manage the Azure Data Lake Storage resources.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Configure access control lists (ACL) for the Azure Data Lake Storage account.
- B. Assign Azure AD security groups to Azure Data Lake Storage.
- C. Configure service-to-service authentication for the Azure Data Lake Storage account.
- D. Configure end-user authentication for the Azure Data Lake Storage account.
- E. Create security groups in Azure Active Directory (Azure AD) and add project members.
Answer: A,B,E
Explanation:
Explanation
References:
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-secure-data
NEW QUESTION 87
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need setup monitoring for tiers 6 through 8.
What should you configure?
- A. an alert rule to monitor storage percentage in databases that emails data engineers
- B. an alert rule to monitor CPU percentage in databases that emails data engineers
- C. an alert rule to monitor storage percentage in elastic pools that emails data engineers
- D. an alert rule to monitor CPU percentage in elastic pools that emails data engineers
- E. extended events for average storage percentage that emails data engineers
Answer: C
Explanation:
Scenario:
Tiers 6 through 8 must have unexpected resource storage usage immediately reported to data engineers.
Tier 3 and Tier 6 through Tier 8 applications must use database density on the same server and Elastic pools in a cost-effective manner.
Topic 3, Litware, inc
Overview
General Overview
Litware, Inc, is an international car racing and manufacturing company that has 1,000 employees. Most employees are located in Europe. The company supports racing teams that complete in a worldwide racing series.
Physical Locations
Litware has two main locations: a main office in London, England, and a manufacturing plant in Berlin, Germany.
During each race weekend, 100 engineers set up a remote portable office by using a VPN to connect the datacentre in the London office. The portable office is set up and torn down in approximately 20 different countries each year.
Existing environment
Race Central
During race weekends, Litware uses a primary application named Race Central. Each car has several sensors that send real-time telemetry data to the London datacentre. The data is used for real-time tracking of the cars.
Race Central also sends batch updates to an application named Mechanical Workflow by using Microsoft SQL Server Integration Services (SSIS).
The telemetry data is sent to a MongoDB database. A custom application then moves the data to databases in SQL Server 2017. The telemetry data in MongoDB has more than 500 attributes. The application changes the attribute names when the data is moved to SQL Server 2017.
The database structure contains both OLAP and OLTP databases.
Mechanical Workflow
Mechanical Workflow is used to track changes and improvements made to the cars during their lifetime.
Currently, Mechanical Workflow runs on SQL Server 2017 as an OLAP system.
Mechanical Workflow has a named Table1 that is 1 TB. Large aggregations are performed on a single column of Table 1.
Requirements
Planned Changes
Litware is the process of rearchitecting its data estate to be hosted in Azure. The company plans to decommission the London datacentre and move all its applications to an Azure datacentre.
Technical Requirements
Litware identifies the following technical requirements:
* Data collection for Race Central must be moved to Azure Cosmos DB and Azure SQL Database. The data must be written to the Azure datacentre closest to each race and must converge in the least amount of time.
* The query performance of Race Central must be stable, and the administrative time it takes to perform optimizations must be minimized.
* The datacentre for Mechanical Workflow must be moved to Azure SQL data Warehouse.
* Transparent data encryption (IDE) must be enabled on all data stores, whenever possible.
* An Azure Data Factory pipeline must be used to move data from Cosmos DB to SQL Database for Race Central. If the data load takes longer than 20 minutes, configuration changes must be made to Data Factory.
* The telemetry data must migrate toward a solution that is native to Azure.
* The telemetry data must be monitored for performance issues. You must adjust the Cosmos DB Request Units per second (RU/s) to maintain a performance SLA while minimizing the cost of the Ru/s.
Data Masking Requirements
During rare weekends, visitors will be able to enter the remote portable offices. Litware is concerned that some proprietary information might be exposed. The company identifies the following data masking requirements for the Race Central data that will be stored in SQL Database:
* Only show the last four digits of the values in a column named SuspensionSprings.
* Only Show a zero value for the values in a column named ShockOilWeight.
NEW QUESTION 88
You have an Azure data factory.
You need to ensure that pipeline-run data is retained for 120 days. The solution must ensure that you can query the data by using the Kusto query language.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Answer:
Explanation:
Explanation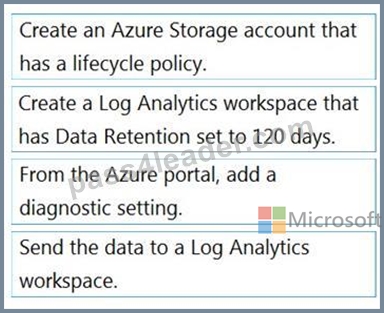
Step 1: Create an Azure Storage account that has a lifecycle policy
To automate common data management tasks, Microsoft created a solution based on Azure Data Factory.
The service, Data Lifecycle Management, makes frequently accessed data available and archives or purges other data according to retention policies. Teams across the company use the service to reduce storage costs, improve app performance, and comply with data retention policies.
Step 2: Create a Log Analytics workspace that has Data Retention set to 120 days.
Data Factory stores pipeline-run data for only 45 days. Use Azure Monitor if you want to keep that data for a longer time. With Monitor, you can route diagnostic logs for analysis to multiple different targets, such as a Storage Account: Save your diagnostic logs to a storage account for auditing or manual inspection. You can use the diagnostic settings to specify the retention time in days.
Step 3: From Azure Portal, add a diagnostic setting.
Step 4: Send the data to a log Analytics workspace,
Event Hub: A pipeline that transfers events from services to Azure Data Explorer.
Keeping Azure Data Factory metrics and pipeline-run data.
Configure diagnostic settings and workspace.
Create or add diagnostic settings for your data factory.
In the portal, go to Monitor. Select Settings > Diagnostic settings.
Select the data factory for which you want to set a diagnostic setting.
If no settings exist on the selected data factory, you're prompted to create a setting. Select Turn on diagnostics.
Give your setting a name, select Send to Log Analytics, and then select a workspace from Log Analytics Workspace.
Select Save.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/monitor-using-azure-monitor
NEW QUESTION 89
You are implementing automatic tuning mode for Azure SQL databases.
Automatic tuning is configured as shown in the following table.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.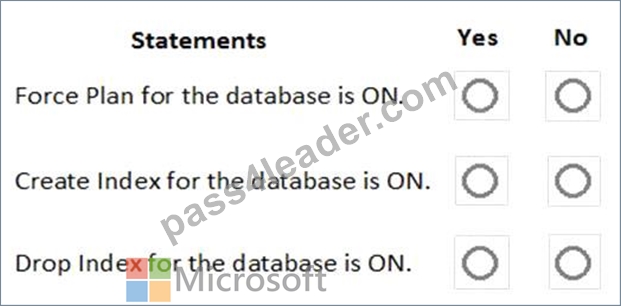
Answer:
Explanation: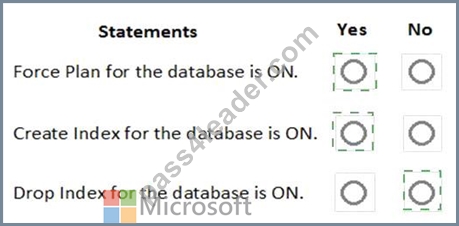
Explanation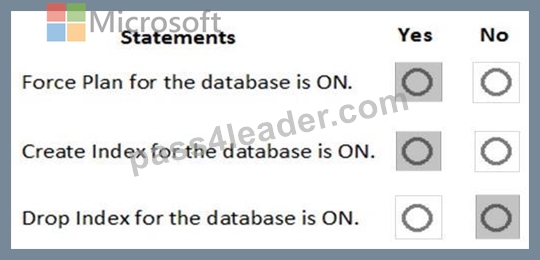
Automatic tuning options can be independently enabled or disabled per database, or they can be configured on SQL Database servers and applied on every database that inherits settings from the server. SQL Database servers can inherit Azure defaults for Automatic tuning settings. Azure defaults at this time are set to FORCE_LAST_GOOD_PLAN is enabled, CREATE_INDEX is enabled, and DROP_INDEX is disabled.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-automatic-tuning
NEW QUESTION 90
You need to build a solution to collect the telemetry data for Race Control.
What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.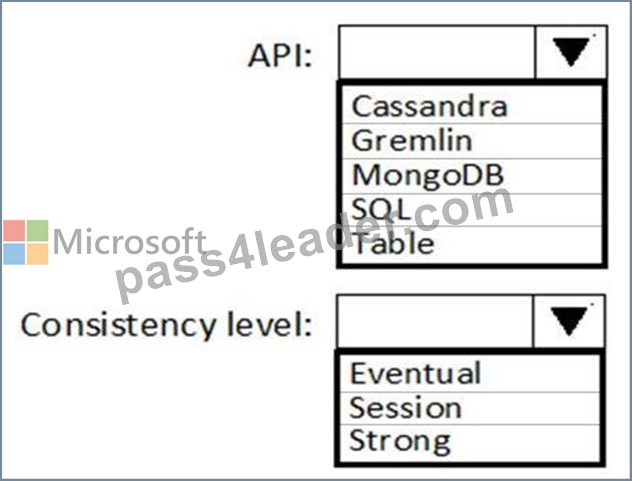
Answer:
Explanation: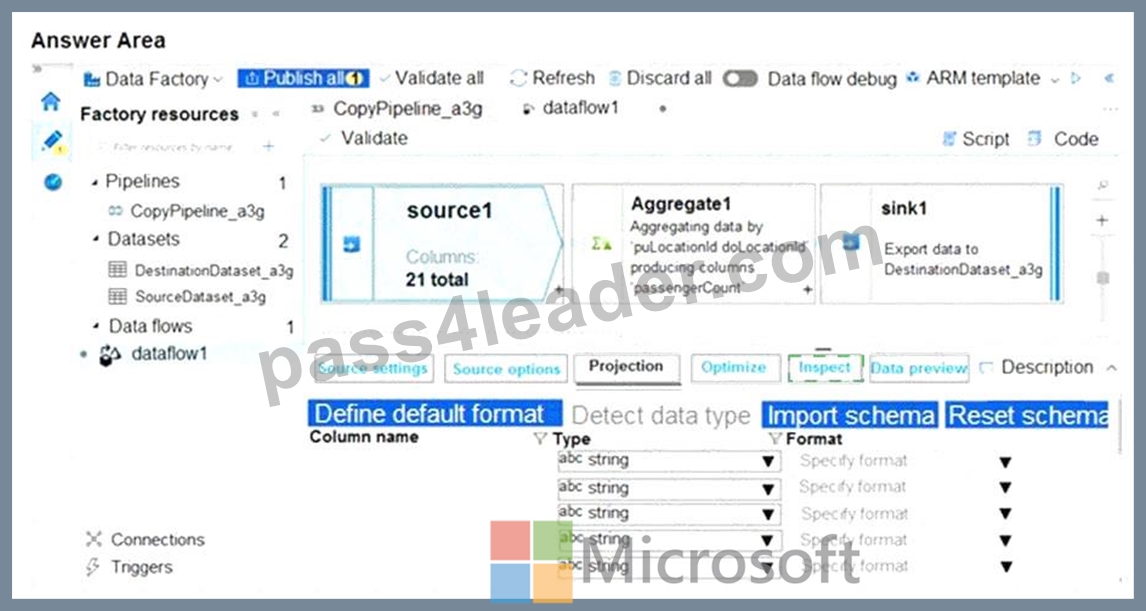
Explanation
API: MongoDB
Consistency level: Strong
Use the strongest consistency Strong to minimize convergence time.
Scenario: The data must be written to the Azure datacentre closest to each race and must converge in the least amount of time.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/consistency-levels
NEW QUESTION 91
You are developing a data engineering solution for a company. The solution will store a large set of key-value pair data by using Microsoft Azure Cosmos DB.
The solution has the following requirements:
* Data must be partitioned into multiple containers.
* Data containers must be configured separately.
* Data must be accessible from applications hosted around the world.
* The solution must minimize latency.
You need to provision Azure Cosmos DB.
- A. Configure table-level throughput.
- B. Provision an Azure Cosmos DB account with the Azure Table API. Enable multi-region writes.
- C. Provision an Azure Cosmos DB account with the Azure Table API. Enable geo-redundancy.
- D. Replicate the data globally by manually adding regions to the Azure Cosmos DB account.
- E. Cosmos account-level throughput.
Answer: B
Explanation:
Scale read and write throughput globally. You can enable every region to be writable and elastically scale reads and writes all around the world. The throughput that your application configures on an Azure Cosmos database or a container is guaranteed to be delivered across all regions associated with your Azure Cosmos account.
The provisioned throughput is guaranteed up by financially backed SLAs.
References:
https://docs.microsoft.com/en-us/azure/cosmos-db/distribute-data-globally
NEW QUESTION 92
Your company uses Microsoft Azure SQL Database configure with Elastic pool. You use Elastic Database jobs to run queries across all databases in the pod.
You need to analyze, troubleshoot, and report on components responsible for running Elastic Database jobs.
You need to determine the component responsible for running job service tasks.
Which components should you use for each Elastic pool job services task? To answer, drag the appropriate component to the correct task. Each component may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-job-automation-overview
NEW QUESTION 93
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop data engineering solutions for a company.
A project requires the deployment of resources to Microsoft Azure for batch data processing on Azure HDInsight. Batch processing will run daily and must:
Scale to minimize costs
Be monitored for cluster performance
You need to recommend a tool that will monitor clusters and provide information to suggest how to scale.
Solution: Monitor clusters by using Azure Log Analytics and HDInsight cluster management solutions.
Does the solution meet the goal?
- A. No
- B. Yes
Answer: B
Explanation:
Explanation
HDInsight provides cluster-specific management solutions that you can add for Azure Monitor logs.
Management solutions add functionality to Azure Monitor logs, providing additional data and analysis tools.
These solutions collect important performance metrics from your HDInsight clusters and provide the tools to search the metrics. These solutions also provide visualizations and dashboards for most cluster types supported in HDInsight. By using the metrics that you collect with the solution, you can create custom monitoring rules and alerts.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-oms-log-analytics-tutorial
NEW QUESTION 94
You have a table named SalesFact in an Azure SQL data warehouse. SalesFact contains sales data from the past 36 months and has the following characteristics:
* Is partitioned by month
* Contains one billion rows
* Has clustered columnstore indexes
All the beginning of each month, you need to remove data SalesFact that is older than 36 months as quickly as possible.
Which three actions should you perform in sequence in a stored procedure? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.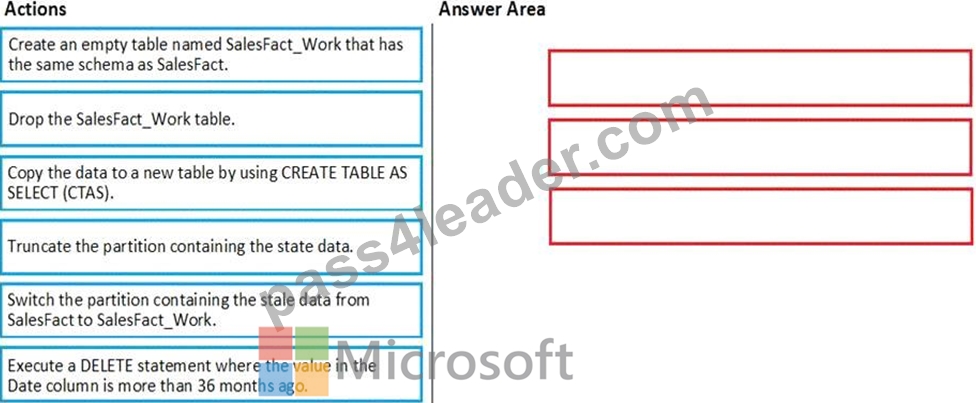
Answer:
Explanation: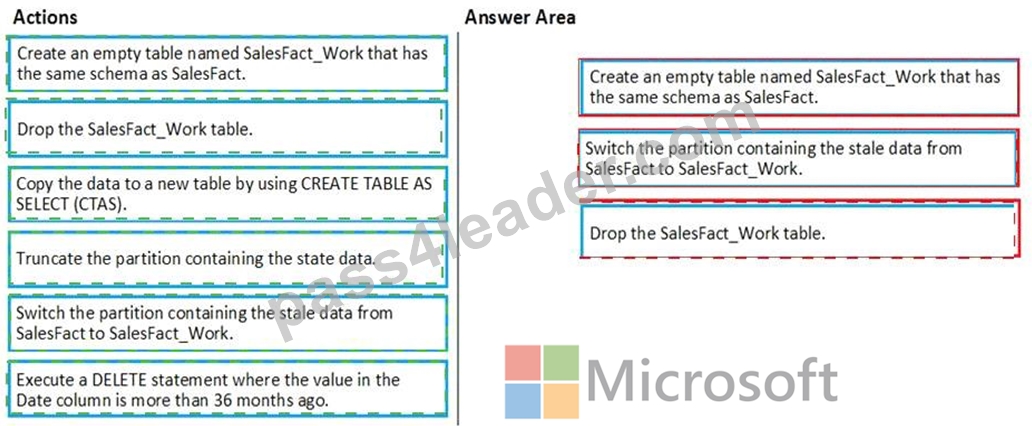
Explanation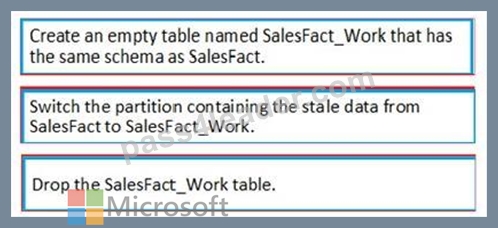
Step 1: Create an empty table named SalesFact_work that has the same schema as SalesFact.
Step 2: Switch the partition containing the stale data from SalesFact to SalesFact_Work.
SQL Data Warehouse supports partition splitting, merging, and switching. To switch partitions between two tables, you must ensure that the partitions align on their respective boundaries and that the table definitions match.
Loading data into partitions with partition switching is a convenient way stage new data in a table that is not visible to users the switch in the new data.
Step 3: Drop the SalesFact_Work table.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-partition
NEW QUESTION 95
You are a data engineer. You are designing a Hadoop Distributed File System (HDFS) architecture. You plan to use Microsoft Azure Data Lake as a data storage repository.
You must provision the repository with a resilient data schema. You need to ensure the resiliency of the Azure Data Lake Storage. What should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation
Box 1: NameNode
An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients.
Box 2: DataNode
The DataNodes are responsible for serving read and write requests from the file system's clients.
Box 3: DataNode
The DataNodes perform block creation, deletion, and replication upon instruction from the NameNode.
Note: HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system's clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
References:
https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#NameNode+and+DataNodes
NEW QUESTION 96
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to configure data encryption for external applications.
Solution:
1. Access the Always Encrypted Wizard in SQL Server Management Studio
2. Select the column to be encrypted
3. Set the encryption type to Deterministic
4. Configure the master key to use the Windows Certificate Store
5. Validate configuration results and deploy the solution
Does the solution meet the goal?
- A. No
- B. Yes
Answer: A
Explanation:
Explanation
Use the Azure Key Vault, not the Windows Certificate Store, to store the master key.
Note: The Master Key Configuration page is where you set up your CMK (Column Master Key) and select the key store provider where the CMK will be stored. Currently, you can store a CMK in the Windows certificate store, Azure Key Vault, or a hardware security module (HSM).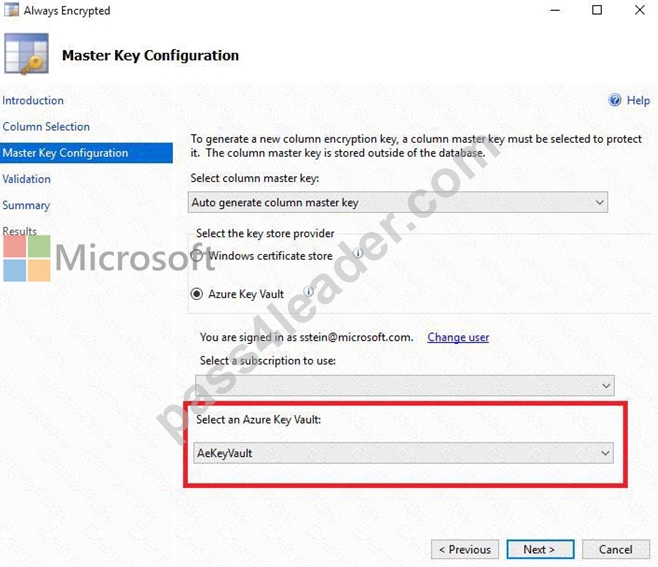
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-always-encrypted-azure-key-vault
Topic 2, Proseware Inc
Background
Proseware, Inc, develops and manages a product named Poll Taker. The product is used for delivering public opinion polling and analysis.
Polling data comes from a variety of sources, including online surveys, house-to-house interviews, and booths at public events.
Polling data
Polling data is stored in one of the two locations:
* An on-premises Microsoft SQL Server 2019 database named PollingData
* Azure Data Lake Gen 2
Data in Data Lake is queried by using PolyBase
Poll metadata
Each poll has associated metadata with information about the poll including the date and number of respondents. The data is stored as JSON.
Phone-based polling
Security
* Phone-based poll data must only be uploaded by authorized users from authorized devices
* Contractors must not have access to any polling data other than their own
* Access to polling data must set on a per-active directory user basis
Data migration and loading
* All data migration processes must use Azure Data Factory
* All data migrations must run automatically during non-business hours
* Data migrations must be reliable and retry when needed
Performance
After six months, raw polling data should be moved to a lower-cost storage solution.
Deployments
* All deployments must be performed by using Azure DevOps. Deployments must use templates used in multiple environments
* No credentials or secrets should be used during deployments
Reliability
All services and processes must be resilient to a regional Azure outage.
Monitoring
All Azure services must be monitored by using Azure Monitor. On-premises SQL Server performance must be monitored.
NEW QUESTION 97
You manage an enterprise data warehouse in Azure Synapse Analytics.
Users report slow performance when they run commonly used queries. Users do not report performance changes for infrequently used queries.
You need to monitor resource utilization to determine the source of the performance issues.
Which metric should you monitor?
- A. Data IO percentage
- B. DWU limit
- C. Data Warehouse Units (DWU) used
- D. Cache hit percentage
Answer: D
Explanation:
The Azure Synapse Analytics storage architecture automatically tiers your most frequently queried columnstore segments in a cache residing on NVMe based SSDs designed for Gen2 data warehouses. Greater performance is realized when your queries retrieve segments that are residing in the cache. You can monitor and troubleshoot slow query performance by determining whether your workload is optimally leveraging the Gen2 cache.
Note: As of November 2019, Azure SQL Data Warehouse is now Azure Synapse Analytics.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-how-to-monitor-cache
https://docs.microsoft.com/bs-latn-ba/azure/sql-data-warehouse/sql-data-warehouse-concept-resource-utilization-query-activity
NEW QUESTION 98
You develop data engineering solutions for a company. The company has on-premises Microsoft SQL Server databases at multiple locations.
The company must integrate data with Microsoft Power BI and Microsoft Azure Logic Apps. The solution must avoid single points of failure during connection and transfer to the cloud. The solution must also minimize latency.
You need to secure the transfer of data between on-premises databases and Microsoft Azure.
What should you do?
- A. Install an on-premises data gateway in personal mode at each location
- B. Install an Azure on-premises data gateway as a cluster at each location
- C. Install a standalone on-premises Azure data gateway at each location
- D. Install an Azure on-premises data gateway at the primary location
Answer: B
Explanation:
Explanation
You can create high availability clusters of On-premises data gateway installations, to ensure your organization can access on-premises data resources used in Power BI reports and dashboards. Such clusters allow gateway administrators to group gateways to avoid single points of failure in accessing on-premises data resources. The Power BI service always uses the primary gateway in the cluster, unless it's not available. In that case, the service switches to the next gateway in the cluster, and so on.
References:
https://docs.microsoft.com/en-us/power-bi/service-gateway-high-availability-clusters
NEW QUESTION 99
You develop data engineering solutions for a company. You must migrate data from Microsoft Azure Blob storage to an Azure SQL Data Warehouse for further transformation. You need to implement the solution.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.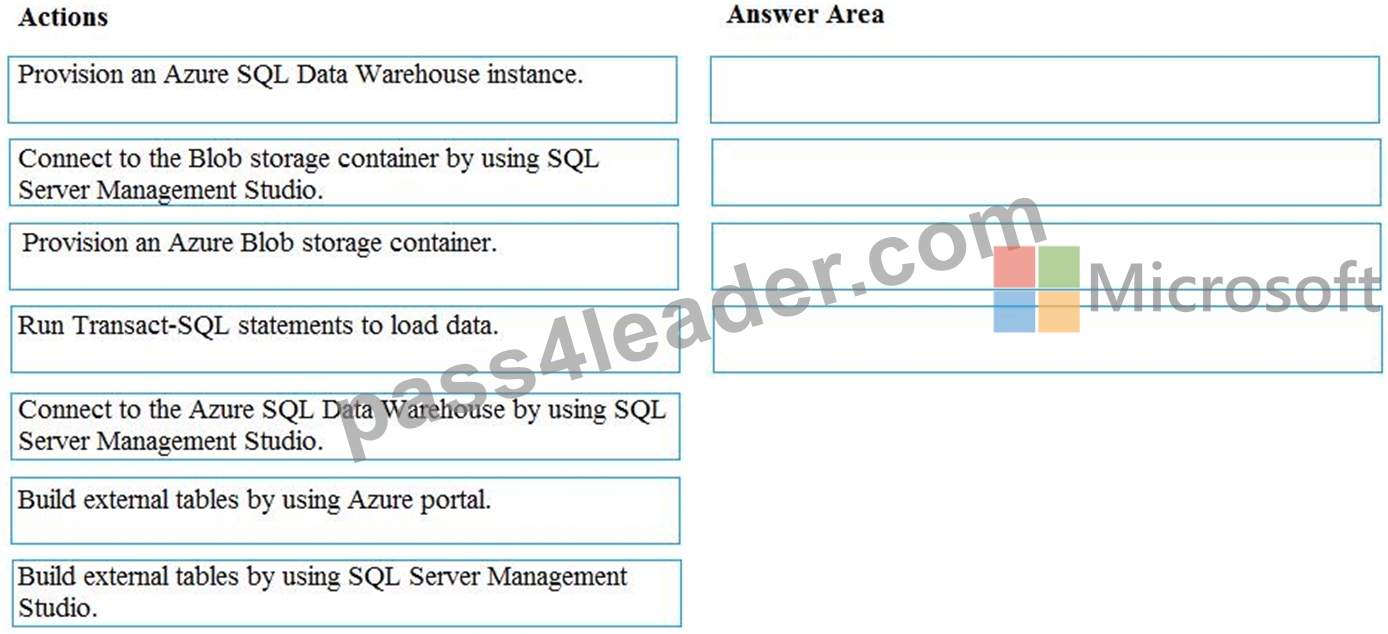
Answer:
Explanation:
References:
https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/sql-data-warehouse/load-data-from-azure-blob-storage-using-polybase.md
NEW QUESTION 100
Use the following login credentials as needed:
Azure Username: xxxxx
Azure Password: xxxxx
The following information is for technical support purposes only:
Lab Instance: 10277521
You plan to deploy an integration runtime named Runtime1 to an Azure virtual machine.
You need to create an Azure Data Factory V2, and then prepare the required Data Factory resources for App1.
To complete this task, sign in to the Azure portal.
Answer:
Explanation:
Step 1: Create an Azure Data Factory V2
1. Go to the Azure portal.
2. Select Create a resource on the left menu, select Analytics, and then select Data Factory.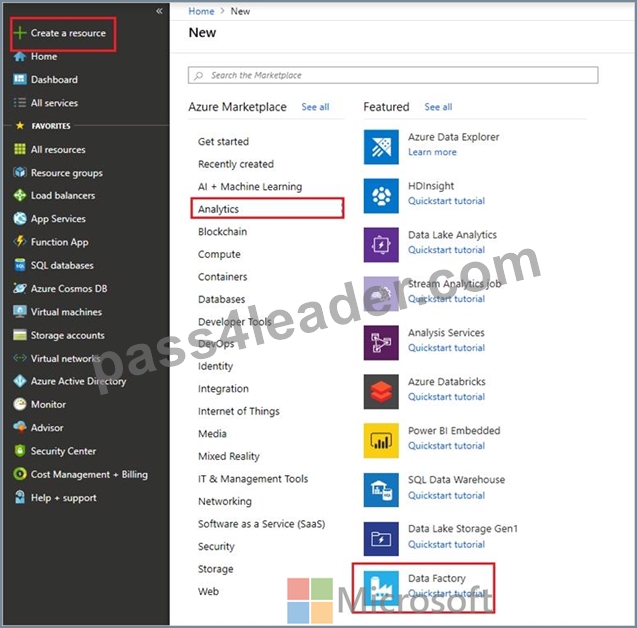
4. On the New data factory page, enter a name.
5. For Subscription, select your Azure subscription in which you want to create the data factory.
6. For Resource Group, use one of the following steps:
7. For Version, select V2.
8. For Location, select the location for the data factory.
9. Select Create.
10. After the creation is complete, you see the Data Factory page.
Step 2: Setup of the Integration Runtime Runtime1
High-level steps for creating a linked self-hosted IR
1. In the self-hosted IR Runtime to be shared, click Connections and Grant permission to another Data Factory. .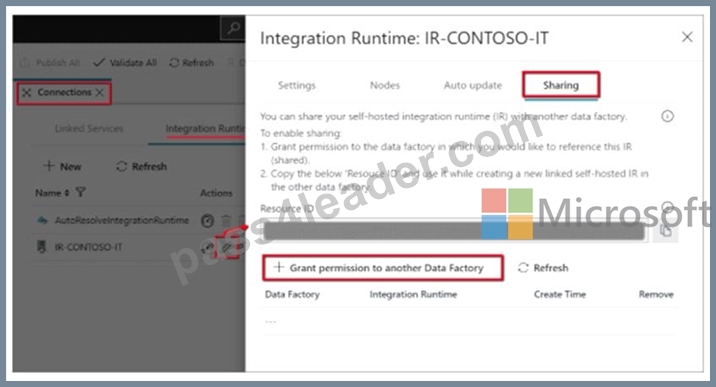
2. Select the data factory you just created.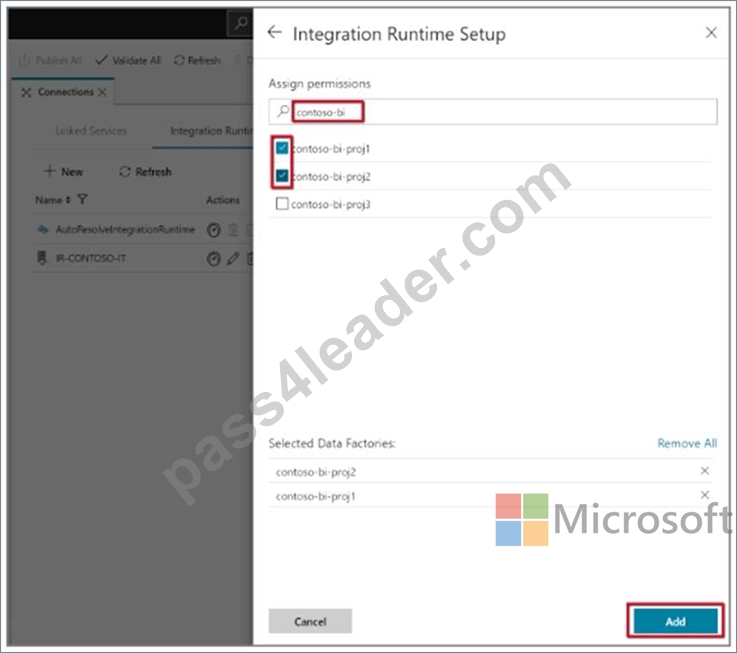
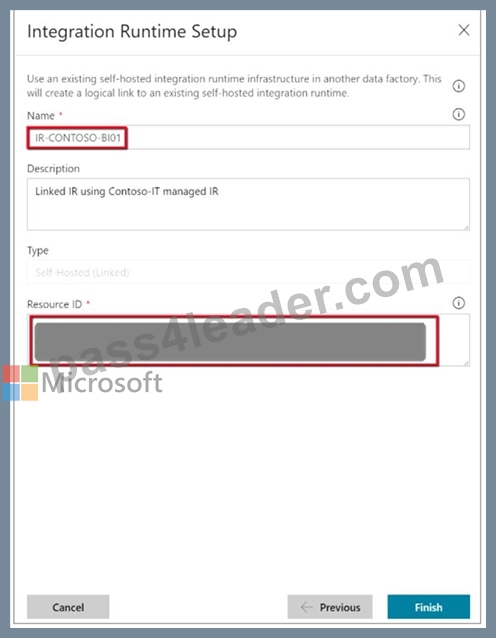
Note the resource ID of the self-hosted IR to be shared.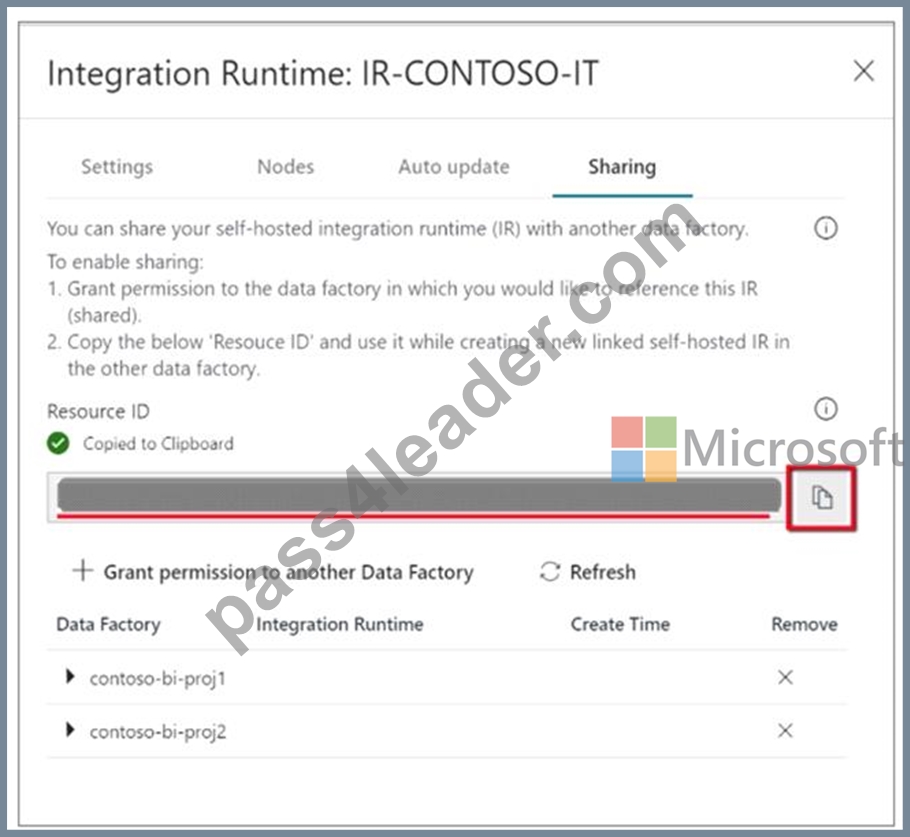
3. In the data factory to which the permissions were granted, create a new self-hosted IR (linked) and enter the resource ID.
References:
https://docs.microsoft.com/en-us/azure/data-factory/quickstart-create-data-factory-portal
https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime#sharing-the-self-hosted-integration-runtime-ir-with-multiple-data-factories
NEW QUESTION 101
You develop data engineering solutions for a company.
A project requires analysis of real-time Twitter feeds. Posts that contain specific keywords must be stored and processed on Microsoft Azure and then displayed by using Microsoft Power BI. You need to implement the solution.
Which five actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation: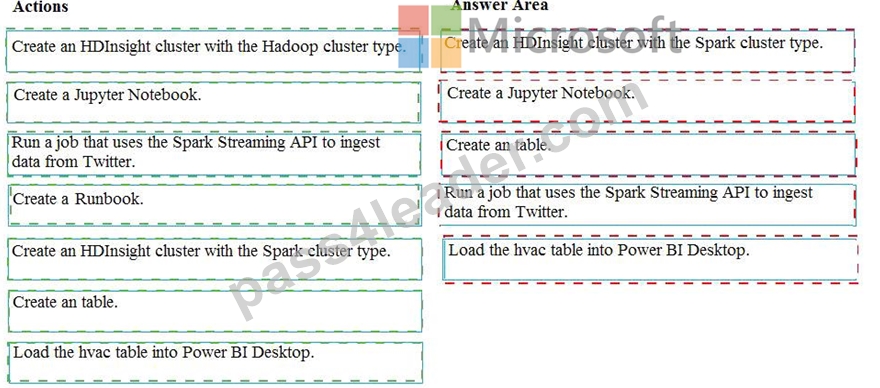
Explanation
Step 1: Create an HDInisght cluster with the Spark cluster type
Step 2: Create a Jyputer Notebook
Step 3: Create a table
The Jupyter Notebook that you created in the previous step includes code to create an hvac table.
Step 4: Run a job that uses the Spark Streaming API to ingest data from Twitter Step 5: Load the hvac table into Power BI Desktop You use Power BI to create visualizations, reports, and dashboards from the Spark cluster data.
References:
https://acadgild.com/blog/streaming-twitter-data-using-spark
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-use-with-data-lake-store
NEW QUESTION 102
......
Tested Material Used To DP-200 Test Engine: https://www.pass4leader.com/Microsoft/DP-200-exam.html